What Are Image-to-Image Translation Models?

In the dynamic world of digital imagery and visual content, the ability to effortlessly transform one image into another, adapting its style, context, or even underlying structure, once seemed like the stuff of science fiction. Today, thanks to the revolutionary advancements in artificial intelligence, this “magic” is encapsulated within a powerful paradigm known as Image-to-Image (I2I) Translation. At Tophinhanhdep.com, we understand the profound impact these models have on how we create, curate, and experience visual media, from stunning wallpapers and bespoke backgrounds to professional digital photography and cutting-edge visual design.

Image-to-Image translation models are a sophisticated class of deep learning algorithms designed to learn the mapping between an input image and a desired output image. Imagine having a photograph taken on a cloudy day and instantly transforming it into a clear night sky, or taking a simple sketch and rendering it into a photorealistic masterpiece. This isn’t merely about applying filters; it’s about understanding the underlying semantic content of an image and intelligently re-synthesizing it into a new visual domain while preserving critical elements. For anyone involved in photography, graphic design, or simply seeking image inspiration for their mood boards or thematic collections, I2I translation offers an unparalleled level of creative freedom and efficiency.
These models are the backbone of many advanced image tools, including sophisticated AI upscalers, and enable intricate photo manipulation that was previously painstakingly manual. They empower users to generate diverse photo ideas, explore various editing styles, and bring creative ideas to life with unprecedented ease. Tophinhanhdep.com is at the forefront of exploring and explaining these technologies, helping our community leverage their potential for everything from crafting beautiful photography to developing unique abstract art.
![]()
The Core Concept: Learning Visual Transformations
At its heart, image-to-image translation is about teaching a machine to “see” an image in one way and “redraw” it in another, adhering to a new set of rules or characteristics. This process moves beyond simple pixel-level adjustments; it delves into recognizing patterns, textures, and structures to perform intelligent transformations.
Defining Image-to-Image Translation
Image-to-image translation involves converting images from a source domain to a target domain while ensuring the semantic content of the images remains intact. Different “domains” refer to distinct visual attributes such as day versus night, grayscale versus color, or even transforming a detailed map into a satellite image. The goal is to learn a complex mapping function that can translate features from one visual representation to another.
Consider the vast array of images available on Tophinhanhdep.com – from tranquil nature scenes to vibrant abstract compositions. I2I translation allows for incredible flexibility:
- Aesthetic Transformations: Change the mood of a photo from sad/emotional to uplifting, or adapt an image to fit a specific aesthetic trend.
- Contextual Changes: Convert a daytime background into a nighttime one, or modify weather conditions in a wallpaper.
- Style Transfer: Apply the artistic style of a famous painting to your own photography, creating truly unique digital art.
- Content Generation: Generate variations of existing stock photos to fit diverse editorial needs, or create entirely new visual elements for graphic design projects.
These capabilities are a game-changer for content creators looking to explore trending styles or expand their image collections with minimal effort. It’s akin to having an infinitely versatile artist at your fingertips, capable of rendering any vision.
The Generative Approach: GANs and Their Foundation
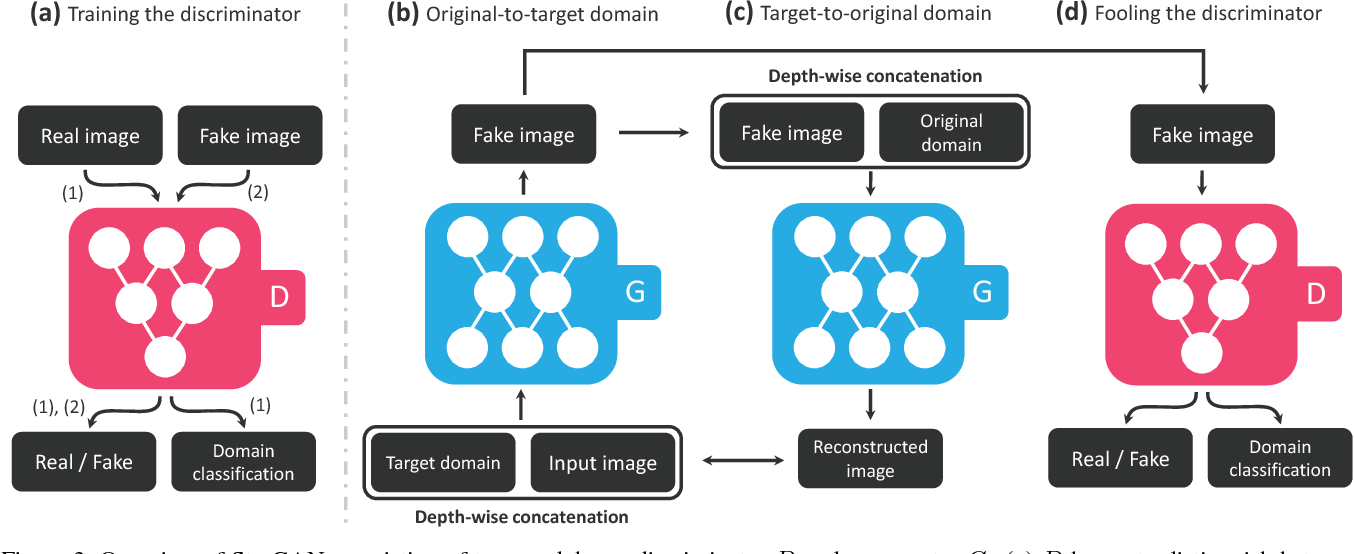
Many foundational image-to-image translation models, and generative AI models in general, owe their power to Generative Adversarial Networks (GANs). Introduced by Ian Goodfellow and his colleagues, GANs operate on an ingenious adversarial principle, pitting two neural networks against each other in a continuous learning game.
The architecture of a GAN consists of two primary components:
- The Generator (G): This network’s job is to create new data instances that resemble the real data. In the context of image translation, it takes an input image (from the source domain) and attempts to produce a corresponding image in the target domain.
- The Discriminator (D): This network acts as a critic. It takes both real images (from the target domain) and fake images (generated by G) and tries to distinguish which are real and which are synthesized.
The two networks train together in an adversarial manner. The generator constantly tries to “fool” the discriminator into believing its generated images are real, while the discriminator continuously improves its ability to detect fakes. This competitive process drives both networks to improve dramatically, resulting in a generator that can produce incredibly realistic and convincing translated images.
For photography enthusiasts and professionals, this means new avenues for photo manipulation and editing styles. Imagine generating an entire series of beautiful photography with consistent stylistic changes, or instantly adding elements to a scene that weren’t originally there. GANs, and their image-to-image derivatives, pave the way for a new era of creative control in digital photography.
Advancements in Image-to-Image Translation: From Paired to Unpaired and Beyond
The evolution of I2I models has been rapid, addressing increasing complexities and opening up new possibilities. Early models often required “paired” training data, meaning each input image had a precisely corresponding output image. However, real-world data rarely comes so neatly packaged. This led to the development of “unpaired” translation methods, significantly broadening the scope of applications.
Conditional GANs and Paired Image Translation (Pix2Pix)
One of the most influential early models for paired image-to-image translation was Pix2Pix, detailed in Dr. Jason Brownless’s work on developing GANs for image translation. This model, essentially a conditional GAN, learns a mapping from an input image to an output image where explicit correspondences exist in the training dataset.
In Pix2Pix, the generator often employs a U-Net architecture, which is excellent for retaining fine-grained details during the translation process. The discriminator then evaluates the generated output alongside the original input, determining if the generated image is a plausible translation. The training typically includes not only the adversarial loss but also an L1 loss, which encourages the generated image to be pixel-wise close to the ground truth output, leading to faster convergence and more stable results.
Consider its applications on Tophinhanhdep.com:
- Graphic Design & Digital Art: Transforming wireframes or sketches into fully rendered images, or converting line drawings into shaded illustrations. This is invaluable for creative ideas in visual design.
- Photo Reconstruction: Reconstructing full images from edge maps, or adding color to grayscale images (colorization). This directly impacts editing styles and enhances existing photography.
- Scientific Visualization: As seen in the example of mechanical networks, Pix2Pix can automatically draw connections (bonds) on images containing only points, providing critical structural information for analysis. This demonstrates its power to augment scientific or technical images.
The success of Pix2Pix showcased the immense potential of GANs for practical image transformation tasks, laying the groundwork for more advanced models.
Unpaired Image Translation with CycleGAN
While Pix2Pix excelled with paired data, collecting such datasets can be incredibly challenging or even impossible for many tasks (e.g., transforming a horse into a zebra while keeping the background identical). This limitation spurred the development of models like CycleGAN, also highlighted on Tophinhanhdep.com’s resources. CycleGAN (along with concurrent works like DiscoGAN and DualGAN) addresses the problem of unpaired image-to-image translation.
The core innovation of CycleGAN is its “cycle consistency loss.” It postulates that if you translate an image from domain A to domain B, and then translate the resulting image back from domain B to domain A, you should ideally arrive back at your original image. This “round trip” consistency allows the model to learn meaningful translations without needing direct paired examples. CycleGAN uses two generators (G: A→B and F: B→A) and two discriminators (one for each domain).
CycleGAN’s implications for Tophinhanhdep.com’s users are vast:
- Season Transfer: Changing a summer scene into a winter one, or vice-versa, for nature photography or wallpapers.
- Style Transfer (without paired examples): Applying a specific artistic editing style from one collection of images to another, ideal for creating unified thematic collections or experimenting with trending styles.
- Object Transfiguration: As in the classic horse-to-zebra example, changing one object type to another while maintaining the scene’s composition. This provides boundless opportunities for photo manipulation and generating creative ideas.
The ability to perform translation without paired datasets opened the floodgates for more flexible and real-world applicable image transformation tasks, significantly enriching the possibilities for visual design and creative content generation.
The Rise of Diffusion Models and img2img-Turbo
More recently, diffusion models have emerged as powerful contenders in the generative AI space, often outperforming GANs in terms of image quality and diversity, particularly for high-fidelity image generation. Diffusion models work by gradually adding noise to an image until it becomes pure noise, then learning to reverse this process, “denoising” the image back to its original form. This iterative refinement allows them to generate incredibly detailed and realistic outputs.
While traditional diffusion models can be computationally expensive due to their multi-step nature, innovations are constantly pushing the boundaries of efficiency. One such breakthrough, as highlighted in “A new tool for image-to-image translation: img2img-Turbo!” on Tophinhanhdep.com, is img2img-Turbo. This project introduces CycleGAN-Turbo and pix2pix-Turbo, models capable of achieving high-quality image translation in a single step.
Key aspects of img2img-Turbo and its underlying principles:
- Single-Step Translation: This drastically reduces computational cost and inference time, making it suitable for real-time applications and rapid iteration in visual design and photography editing.
- Leveraging Pre-trained Diffusion Models: img2img-Turbo models exploit the capabilities of powerful pre-trained text-to-image diffusion models like Stable Diffusion. This allows them to inherit the ability to produce remarkably realistic and high resolution images.
- Content Control with Text Prompts: A revolutionary feature, users can guide the translation process using natural language descriptions. For instance, transforming an image from “night scene” to “daytime scene” can be achieved with a simple text prompt. This seamlessly integrates with “Image Tools” that feature Image-to-Text capabilities, offering unprecedented control for generating specific photo ideas or tailoring aesthetic outcomes.
- Structural Integrity Preservation: Through innovative architectural elements like LoRA Adapters, Skip Connections, and Zero-Convolutions, img2img-Turbo ensures that the fundamental structure and layout of the input image are meticulously maintained, preventing unrealistic artifacts often seen in older models. This is crucial for maintaining the quality and authenticity of beautiful photography and digital art.
These “Turbo” models represent a paradigm shift, combining the best of GAN architectures with the fidelity of diffusion models and the user-friendliness of text-based control. For Tophinhanhdep.com, this translates into advanced functionalities for users to transform wallpapers, enhance backgrounds, experiment with complex editing styles, and bring sophisticated creative ideas to fruition with speed and precision.
Image-to-Image Translation in Practice: Tophinhanhdep.com’s Vision
The theoretical foundations and technological advancements in image-to-image translation are incredibly exciting, but their true value lies in their practical application. At Tophinhanhdep.com, we envision and implement these technologies to empower our users with the best possible image tools and creative resources.
Enhancing Visual Content with I2I
Image-to-image translation models are not just research curiosities; they are powerful engines for enhancing, customizing, and generating visual content across all categories Tophinhanhdep.com specializes in:
- Wallpapers & Backgrounds: Users can take an existing wallpaper and effortlessly change its color palette, apply a new artistic style, or alter environmental conditions (e.g., sunny to moody). This allows for deep personalization and alignment with specific aesthetic preferences or design briefs.
- Aesthetic & Nature Photography: I2I enables photographers to experiment with editing styles that transform the mood of a nature shot, enhance lighting, or even simulate different times of day. A simple prompt could shift a lush forest into an autumn wonderland, or add dramatic clouds to a clear sky, moving into realms of beautiful photography with artistic flair.
- Abstract & Emotional Images: For abstract art, I2I can generate endless variations from a single input, exploring new textures, patterns, and color schemes. For sad/emotional imagery, it can subtly shift visual cues to amplify or alter the emotional impact, allowing artists to fine-tune their message.
- High-Resolution Stock Photos: Beyond mere compressors or converters, I2I-powered AI upscalers can genuinely improve image quality, inferring details to achieve truly high resolution outputs from lower-res inputs. This is crucial for stock photos that need to be adaptable across various media. I2I can also modify elements within stock photos to fit specific client briefs without needing reshoots.
- Digital Art & Graphic Design: I2I serves as an indispensable assistant for graphic design and digital art. It can translate rough concept sketches into detailed renderings, transform text prompts into visual elements, or help artists experiment with complex photo manipulation ideas quickly. Generating elements for a collage or turning 2D designs into simulated 3D assets becomes significantly easier.
- Creative Image Tools: Within our suite of image tools, I2I features can be integrated for advanced optimization. Imagine an optimizer that not only compresses but also visually enhances an image, or a converter that translates formats while simultaneously upgrading visual fidelity. The potential extends to tools that can generate diverse visual concepts from an image-to-text description, fueling new creative ideas.
Creative Freedom and Inspiration
Beyond technical enhancement, image-to-image translation is a wellspring of image inspiration. Designers, artists, and hobbyists can:
- Generate Photo Ideas: Feed an existing photograph into an I2I model with a descriptive prompt to explore hundreds of variations, instantly generating new photo ideas for upcoming projects or compositions.
- Develop Mood Boards: Create coherent mood boards by transforming disparate images into a unified visual style, or generate specific imagery that perfectly matches a conceptual theme.
- Curate Thematic Collections: Easily adapt images to fit specific thematic collections, ensuring consistency in style and content across a diverse set of visuals.
- Experiment with Trending Styles: Keep abreast of trending styles in visual media by using I2I to apply contemporary aesthetics to your existing library of images, providing fresh perspectives without recreating content from scratch.
Tophinhanhdep.com aims to be the premier platform where these advanced capabilities are accessible, understandable, and actionable for everyone. We believe that by democratizing access to such powerful visual design and photography tools, we can unlock an unprecedented level of creativity in our community.
Conclusion: The Future of Visual Transformation
Image-to-image translation models represent a monumental leap forward in artificial intelligence, transforming how we interact with and create visual content. From the pioneering adversarial dynamics of GANs and the practical utility of Pix2Pix and CycleGAN, to the high-fidelity outputs of diffusion models and the real-time efficiency of img2img-Turbo, the field is continuously evolving, pushing the boundaries of what’s possible.
At Tophinhanhdep.com, we are committed to integrating these cutting-edge technologies into our platform, providing our users with sophisticated image tools that go far beyond conventional editing. Whether you’re a professional seeking to elevate your digital photography and visual design projects, or an enthusiast exploring aesthetic possibilities for wallpapers and backgrounds, I2I translation offers a gateway to boundless creativity. It empowers you to refine beautiful photography, generate innovative creative ideas, and ensure your visual content is always at the forefront of trending styles. The future of visual transformation is here, and Tophinhanhdep.com is proud to be your guide in harnessing its extraordinary power.