What is Imagen: Unveiling the Future of Image Generation and Editing on Tophinhanhdep.com

In the rapidly evolving landscape of artificial intelligence, the term “Imagen” has emerged as a beacon of innovation, representing two distinct yet equally transformative forces in the world of visual content. For the vibrant community of Tophinhanhdep.com—enthusiasts of high-quality images, discerning photographers, visual designers, and those seeking endless inspiration—understanding “what is Imagen” is paramount to unlocking new possibilities in image creation, enhancement, and optimization.
Primarily, “Imagen” refers to Google’s groundbreaking text-to-image diffusion model, a sophisticated AI system capable of generating photorealistic, high-resolution images from simple textual descriptions. Released to much acclaim, this iteration of Imagen pushes the boundaries of what was previously thought possible in caption-conditional image generation. It can conjure scenes ranging from the logical to the utterly fantastical, translating abstract concepts and intricate descriptions into vivid visual realities. This capability holds immense potential for creating unique wallpapers, captivating backgrounds, and bespoke digital art, aligning perfectly with Tophinhanhdep.com’s diverse categories like Aesthetic, Nature, Abstract, and Beautiful Photography.
Beyond Google’s generative model, “Imagen” also denotes an AI-powered photo editing software (Imagen AI Ltd.), a personalized assistant for photographers that streamlines the arduous post-production process. This software revolutionizes how photographers manage their workflow, offering intelligent batch editing capabilities that mimic an individual’s unique style with unprecedented speed and accuracy. For Tophinhanhdep.com’s audience, this means a significant leap forward in efficiently preparing high-resolution stock photos, applying consistent editing styles, and refining digital photography for various applications, from commercial use to personal collections.
This comprehensive guide will delve into the intricacies of both facets of “Imagen,” exploring the cutting-edge technology that underpins them and demonstrating how they collectively redefine the creation and manipulation of visual content. We will unpack the mechanisms behind Google’s generative AI, examine the practical advantages of Imagen AI’s editing prowess, and ultimately illustrate how these advancements empower Tophinhanhdep.com users to explore new horizons in images, photography, and visual design.
![]()
How Imagen Works: A Bird’s-Eye View
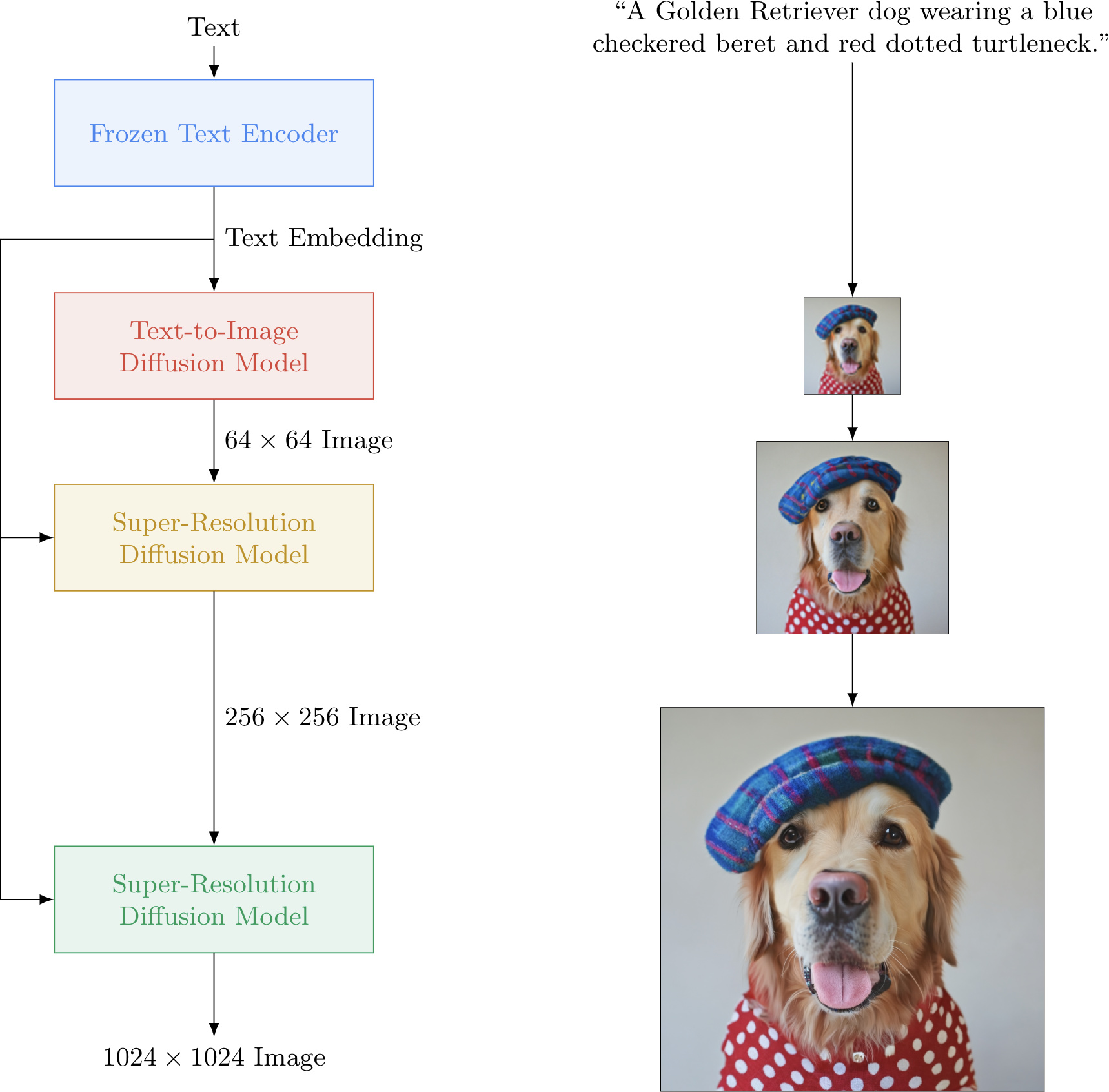
At its core, Google’s Imagen is a complex symphony of machine learning components working in concert to transform textual descriptions into stunning visual art. From a high-level perspective, the process is elegantly structured, moving from linguistic understanding to gradual image refinement.
The journey begins with a textual caption—your creative prompt—which is fed into a text encoder. This sophisticated component translates the human language into a numerical representation, meticulously encapsulating the semantic information contained within your words. This isn’t just a simple keyword extraction; it’s a deep understanding of how words relate, their spatial implications, cardinality, and overall semantic meaning. For Tophinhanhdep.com users envisioning specific “Photo Ideas” or “Thematic Collections,” this deep understanding ensures that a prompt like “a sad dog sitting in the rain with a tiny umbrella” truly yields an image reflecting that emotional nuance and precise scenario.
Following the text encoding, an image-generation model takes center stage. Starting with a field of pure digital noise—often likened to “TV static”—this model iteratively transforms the chaos into a coherent image. Crucially, the text encoding guides this transformation, subtly instructing the model on what elements to depict and how they should be arranged, effectively “telling” it what the caption describes. The initial output from this stage is typically a small, low-resolution image, but one that already visually reflects the input caption. This step is foundational for generating unique “Abstract” or “Creative Ideas” for Tophinhanhdep.com, allowing artists to bring novel concepts to life.

The final, critical stages involve super-resolution models. The small image produced by the generator is passed through a cascade of these models, each tasked with intelligently upscaling and enhancing the image to a progressively higher resolution. These super-resolution models also leverage the initial text encoding, along with the lower-resolution image itself, to “fill in the gaps” of missing information as they quadruple the image size. This multi-stage upsampling process culminates in a remarkably high-resolution image, typically 1024 x 1024 pixels, that is both photorealistic and remarkably faithful to the original textual description. For Tophinhanhdep.com, this means access to stunning “High Resolution” images, ideal for “Wallpapers,” “Backgrounds,” and “Beautiful Photography” that demand exceptional clarity and detail.
This bird’s-eye view reveals a powerful, multi-step pipeline that generates entirely novel images, far beyond merely stitching together existing elements from a database. It represents a significant leap in generative AI, offering unprecedented creative freedom to visual artists and content creators.
How Imagen Works: A Deep Dive
Delving deeper into Imagen’s architecture reveals the ingenious design choices and advanced machine learning techniques that contribute to its unparalleled performance. This section explores the specific components and innovations that empower Imagen to achieve such remarkable results.
Text Encoder
The text encoder, as introduced in our bird’s-eye view, is far more than a simple text-to-number converter; it is the linchpin of Imagen’s understanding. In Google’s Imagen, this critical component is a Transformer encoder, specifically the encoder network of T5 (Text-to-Text Transfer Transformer). T5, a large language model released by Google, is initially trained on vast text-only corpora and is designed to tackle various Natural Language Processing (NLP) tasks by framing them as text-to-text problems.
The significance of using a Transformer-based encoder lies in its ability to comprehend the intricate syntactic structure and semantic relationships between words within a caption. This is achieved through mechanisms like “self-attention,” which allows the model to weigh the importance of different words in relation to each other, irrespective of their position in the sentence. Without this deep contextual understanding, Imagen might generate high-quality images of individual elements but fail to capture the described relationships or the overall scene’s meaning. Imagine trying to create a “sad clown juggling flaming torches” – without understanding “sad” and “juggling” in context, the result could be a cheerful clown or just a clown with torches, missing the emotional core. This robust textual interpretation is crucial for accurately generating images for “Thematic Collections” or conveying specific “Sad/Emotional” moods, as requested on Tophinhanhdep.com.
A crucial design choice by the Imagen authors was to use a large, frozen T5 encoder, meaning it does not learn or change during Imagen’s image generation training. This decision contrasts with some other text-to-image models that use encoders trained specifically on image-caption pairs. The intuition behind Imagen’s approach is that immensely large language models, by virtue of being trained on massive and diverse text-only datasets, develop profoundly powerful and generalized textual representations. These representations, despite not being explicitly optimized for image-text alignment, prove surprisingly effective for guiding image synthesis. The sheer scale and quality of the text data T5 is exposed to provide a rich understanding of the world, which translates directly into superior caption-conditional image generation.
Image Generator
The heart of Imagen’s image creation lies within its Diffusion Model—a type of generative model that has revolutionized the field of AI-driven content generation. Diffusion Models operate on a principle of gradual transformation, first learning to “destroy” data by progressively adding Gaussian noise to training images, then learning to “recover” the original data by reversing this noising process.
Once trained, the Diffusion Model can generate entirely novel images by starting with pure Gaussian noise (random “TV static”) and iteratively denoising it, step-by-step, until a coherent image emerges. This process is highly adaptable, making it ideal for creating diverse visual outputs from “Abstract” concepts to photorealistic scenes.
The critical innovation within Imagen’s image generator is caption conditioning. While a basic Diffusion Model can generate random images resembling its training data, our goal is to produce images that specifically align with a given text caption. Imagen achieves this by injecting the text encoding (the sequence of vectors from the T5 encoder) directly into the diffusion process. These pooled vectors condition the Diffusion Model, teaching it to adapt its denoising procedure to align with the semantic information of the caption. This means that instead of just removing noise randomly, the model learns to remove noise in a way that sculpts an image matching the prompt. This deep integration of textual understanding into the generative process is what allows Imagen to create images reflecting highly specific “Creative Ideas” and intricate “Photo Ideas” for Tophinhanhdep.com users.
Super-Resolution Models
After the image generator produces a small 64x64 pixel image, Imagen employs a cascaded diffusion model approach for super-resolution. This involves two additional Diffusion Models that sequentially upsample the image to its final high-resolution form. The first super-resolution model takes the 64x64 image and upscales it to a medium-sized 256x256 image. The second then takes this 256x256 image and magnifies it to the final, impressive 1024x1024 pixel resolution.
Both super-resolution models are also Diffusion Models, and they are conditioned not only on the text encoding but critically, also on the lower-resolution image they are tasked with upsampling. This dual conditioning allows them to intelligently “fill in” the details, adding realism and coherence as the image grows in size, rather than simply blurring or extrapolating. The architectures of these super-resolution models are typically based on U-Nets, which are neural networks well-suited for image-to-image tasks. Imagen further introduces an Efficient U-Net architecture, optimizing for memory efficiency, faster inference times, and quicker convergence.
Several advanced techniques are integrated into these stages to further boost image quality and text alignment:
- Classifier-Free Guidance: This method enhances image fidelity and caption alignment by training the Diffusion Model to be both conditional (guided by the caption) and unconditional (not guided) simultaneously. During inference, by interpolating between these two modes and magnifying the effect of the conditional gradient, Imagen can produce higher-quality, more aligned samples, even at the cost of some diversity. This is vital for generating “Beautiful Photography” and precise “Aesthetic” images where fidelity to the prompt is paramount.
- Dynamic Thresholding: A critical innovation, especially for achieving photorealism with large guidance weights. Previous models struggled with high guidance weights leading to saturated or unnatural images. Dynamic thresholding addresses this by adaptively scaling pixel values at each timestep, ensuring they remain within a reasonable range [-1, 1]. This technique prevents divergence and oversaturation, leading to significantly better photorealism and alignment, particularly important for producing “High Resolution” and “Nature” images that demand lifelike quality for Tophinhanhdep.com.
- Noise Conditioning Augmentation: Implemented in the super-resolution models, this technique involves corrupting the low-resolution image with Gaussian noise and then conditioning the super-resolution model on this corruption noise level. This makes the models more robust, improving sample quality and their ability to handle potential artifacts from the preceding lower-resolution models, ensuring a clean and sharp final output.
The synergy of these advanced components and techniques—from the deep language understanding of the T5 text encoder to the iterative generation and sophisticated upscaling of cascaded diffusion models, augmented by innovations like classifier-free guidance and dynamic thresholding—is what enables Google’s Imagen to generate images with “unprecedented photorealism and a deep level of language understanding.” This is a game-changer for content creation on platforms like Tophinhanhdep.com, offering an endless wellspring of unique visual assets.
Imagen’s Performance and Innovations
Google’s Imagen didn’t just appear; it set new benchmarks, challenging existing leaders like DALL-E 2. The researchers rigorously evaluated its capabilities, both quantitatively and qualitatively, solidifying its position as a state-of-the-art text-to-image model.
Quantitatively, Imagen achieved a new state-of-the-art zero-shot FID (Fréchet Inception Distance) score of 7.27 on the COCO dataset. FID is a widely recognized metric for measuring image fidelity (how realistic images look), and Imagen outperformed not only DALL-E 2 but also models explicitly trained on COCO. For image-caption alignment (how well the image matches the text), CLIP scores were used, further indicating Imagen’s strong performance.
Qualitative evaluations, often more insightful for creative fields, were equally compelling. Human raters were asked to compare Imagen’s generated images against reference images for photorealism and caption similarity. Imagen achieved a preference rate of 39.2% for photorealism, signifying that humans found its generated images comparably realistic. Crucially, for caption similarity, human raters found Imagen’s outputs to be on par with original reference images, demonstrating its exceptional ability to interpret and visualize complex prompts.
To address shortcomings in existing benchmarks, the Imagen team introduced DrawBench, a comprehensive and challenging set of prompts designed to systematically test various aspects of text-to-image models, including compositionality, cardinality, spatial relations, long-form text, and rare words. In side-by-side comparisons on DrawBench, human raters consistently preferred Imagen over other leading models like DALL-E 2, GLIDE, VQGAN+CLIP, and Latent Diffusion Models, both in terms of image fidelity and image-text alignment. This robust evaluation underscores Imagen’s superior performance across a wide range of creative challenges, making it an invaluable tool for exploring “Creative Ideas” and “Trending Styles” for Tophinhanhdep.com.
The Power of Text Encoder Scaling
A pivotal insight from Imagen’s research, and a key differentiator from its competitors, lies in the profound impact of scaling the text encoder. The researchers discovered that increasing the size of the language model (like T5) in Imagen boosts both sample fidelity and image-text alignment significantly more than increasing the size of the image diffusion model (the U-Net).
This finding suggests that the ability to deeply understand and encode textual prompts is arguably more critical for high-quality text-to-image generation than the raw capacity of the image generation network itself. Imagen leverages an exceptionally large T5-XXL text encoder, far larger than what models like DALL-E 2 utilize (which uses a CLIP text encoder). This emphasis on a powerful, general-purpose language model, trained on massive text-only datasets, allows Imagen to form incredibly rich and nuanced textual representations. These representations then provide a superior “starting point” for the image diffusion model, enabling it to produce more accurate, detailed, and photorealistic images.
For Tophinhanhdep.com’s community, this highlights the growing importance of sophisticated language understanding in visual content creation. It means that the specificity and complexity of your textual prompts can directly translate into the quality and accuracy of the generated “Images” and “Digital Art,” opening doors to truly bespoke creations that perfectly match your artistic vision for “Mood Boards” or “Thematic Collections.”
Imagen AI: The Photographer’s Intelligent Editing Assistant
While Google’s Imagen captivates with its generative prowess, the name “Imagen” also resonates strongly within the professional photography community as an AI-powered photo editing software (Imagen AI Ltd.). This distinct application of AI focuses on revolutionizing the post-production workflow, offering photographers an intelligent assistant that learns and applies their unique editing style at unprecedented speeds. For the photographers among Tophinhanhdep.com’s audience, this Imagen promises to be a game-changer for managing “High Resolution” images, maintaining consistent “Editing Styles,” and optimizing “Digital Photography.”
Imagine dedicating hours to individually adjusting exposure, white balance, contrast, highlights, shadows, clarity, and vibrance for thousands of photos after a shoot. Imagen AI steps in to eliminate this “time-sucking image-by-image editing drudgery.” It’s not just a preset; it’s an AI that understands how you edit and then automates that personalized process across entire batches of photos, often in mere seconds per image.
The core promise of Imagen AI is to save time without compromising quality or personal style. As Imagen co-founder Yotam Gil puts it, the software aims to “break this trade-off and make things both personal and automated.”
Personalized AI Editing Styles
The ultimate power of Imagen AI for professional photographers lies in its ability to create Personal AI Profiles. This feature allows the AI to learn your unique editing style by analyzing your existing library of consistently edited Lightroom catalogs. Imagen AI requires a minimum of 3,000 edited images to build a robust profile that accurately reflects your aesthetic choices. Once trained—a process that typically takes up to 24 hours—this personalized AI “bot” can apply your individual editing style to new, unedited shoots.
This is fundamentally different from traditional presets. While a preset applies an identical, static set of adjustments to every photo, an Imagen Personal AI Profile dynamically tweaks each image individually. It understands varying lighting conditions, scenarios, and subject matter, applying adjustments intelligently to maintain your consistent style across diverse shots. Furthermore, the AI continues to learn and refine your preferences over time through a process called “fine-tuning,” ensuring that its output grows ever closer to your ideal. For Tophinhanhdep.com users who value a distinct “Aesthetic” and want to maintain a signature “Editing Style” across their portfolio or “Thematic Collections,” this personalized approach is invaluable.
Plug-and-Play Talent Profiles and Lite Profiles
For those who are new to Imagen AI, or who don’t yet have the minimum 3,000 edited images for a Personal AI Profile, Imagen offers immediate utility through Talent AI Profiles and Lite Personal AI Profiles.
Talent AI Profiles are ready-to-use, pre-programmed editing styles created from hundreds of thousands of images edited by professional photographers who have partnered with Imagen. These act as “presets on steroids,” allowing users to instantly apply a high-quality, professional editing style to their unedited photos. Tophinhanhdep.com users can experiment with these profiles to find new “Trending Styles” or explore different “Photo Ideas” without investing time in manual editing. The key distinction from traditional presets remains: Talent AI Profiles dynamically adjust each photo rather than applying a blanket filter, ensuring more nuanced and sophisticated results.
The recently introduced Lite Personal AI Profile option provides even greater flexibility. It allows users to create their own AI editing profile based on any existing preset from any photographer or company, without requiring thousands of their own edited images. This is an excellent stepping stone for photographers looking to leverage AI while still maintaining control over their starting aesthetic, or for those who want to quickly convert an existing preset into an intelligent, dynamic AI editing assistant. Both options align with Tophinhanhdep.com’s mission to offer diverse “Editing Styles” and “Creative Ideas” for its community.
Refinement and Control: Fine-Tuning and Adjustments
Imagen AI recognizes that photography is a creative and subjective pursuit, and perfect automation from the outset is rare. Therefore, it provides robust features for users to refine and control the AI’s output, ensuring it aligns precisely with their vision.
Fine-tuning is a crucial aspect of Imagen AI’s learning capability. After you receive a batch of AI-edited photos and make your final manual tweaks in Lightroom, you can upload these “final edits” back to Imagen. The system then analyzes your adjustments and, once enough new data (typically 50% of the original training amount) has been accumulated, it uses this information to build an updated, even more refined Personal or Lite Personal AI Profile. This continuous learning process means the AI gets progressively more accurate and tailored to your specific taste, embodying the spirit of “Photo Manipulation” for nuanced improvements.
For more immediate gratification and control, Profile Adjustments allow users to tweak individual editing parameters (like exposure, contrast, or white balance) for any existing profile—Talent, Personal, or Lite. These changes can then be saved, ensuring that the next time that profile is applied for batch editing, it will reflect your desired overall look. This feature empowers photographers to maintain artistic control while still benefiting from the AI’s speed, critical for achieving a consistent “Aesthetic” across various “Images” and “Photography” types.
Optional AI Tools for Enhanced Workflow
Beyond core editing, Imagen AI offers optional, additional AI-powered services that further streamline the photographer’s workflow, aligning with Tophinhanhdep.com’s “Image Tools” category, especially “Optimizers.” These extras include:
- AI Straightening: Automatically corrects skewed horizons or tilted compositions.
- AI Cropping: Intelligently crops images for better composition, often resulting in surprisingly precise and aesthetically pleasing results.
- AI Subject Masking: This impressive feature not only auto-applies Lightroom’s accurate subject mask but also applies minor smart editing adjustments to the masked area, enhancing the subject’s appearance. This is invaluable for portraiture or any “Beautiful Photography” where the subject needs to stand out.
These optional tools significantly reduce the manual effort involved in preparing images, making the entire process of digital photography more efficient and enjoyable. For Tophinhanhdep.com users dealing with large volumes of “Stock Photos” or diverse “Backgrounds,” these features contribute to quicker turnaround times and a higher standard of readiness for publication.
Transforming Visual Content on Tophinhanhdep.com
The dual nature of “Imagen”—Google’s text-to-image generative AI and Imagen AI’s intelligent photo editing software—presents an unprecedented toolkit for the Tophinhanhdep.com community. These technologies, individually powerful, become even more transformative when considered in synergy, empowering users across all categories from “Images” and “Photography” to “Image Tools” and “Visual Design.”
Google’s Imagen fundamentally changes the paradigm of content creation. No longer are creators limited by existing visual assets or the need for expensive photoshoots. With a detailed text prompt, users can conjure any scene imaginable, generating unique “Wallpapers” and “Backgrounds” tailored precisely to their needs. This opens up endless possibilities for “Aesthetic” explorations, creating bespoke “Nature” scenes, crafting compelling “Abstract” designs, or even visualizing complex “Sad/Emotional” narratives. For “Digital Art” and “Graphic Design,” it’s a powerful engine for generating initial concepts or complete visual compositions, pushing the boundaries of “Creative Ideas” beyond traditional methods. Imagine generating conceptual images for a new product, or an entire “Mood Board” purely from textual descriptions.
Complementing this generative power, Imagen AI Ltd.’s editing software addresses the practical realities of managing and refining visual assets. For photographers, it’s a productivity multiplier for “High Resolution” image processing. It ensures consistency in “Editing Styles” across massive photo collections, turning hours of manual work into minutes. This is crucial for professional “Stock Photos” providers, enabling them to process and deliver high-quality content at scale. Furthermore, the ability to fine-tune AI profiles and utilize optional AI cropping, straightening, and subject masking directly enhances “Photo Manipulation” capabilities, allowing for efficient, personalized refinements that uphold artistic integrity.
The Synergy of Generative AI and AI-Powered Editing
The true revolution for Tophinhanhdep.com users lies in the potential synergy between these two AI powerhouses. Imagine using Google’s Imagen to generate a series of unique, conceptual images—perhaps an “Abstract” representation of a complex idea or a fantastical “Nature” scene. These AI-generated concepts can then be fed into Imagen AI Ltd.’s editing software. Here, a photographer can apply their personalized AI profile, refining the colors, tones, and overall aesthetic of the generated images to match their signature “Editing Style.” This seamless transition from AI generation to AI-assisted editing ensures that even the most imaginative AI-created visuals can be integrated into a cohesive visual brand or “Thematic Collection.”
Moreover, Tophinhanhdep.com’s existing “Image Tools” can further amplify this workflow. “AI Upscalers” can be used on images generated by Google’s Imagen, pushing resolutions even higher or preparing them for large-format prints. “Compressors” and “Optimizers” are essential for preparing these high-resolution, AI-enhanced images for web display, ensuring fast loading times for “Wallpapers” and “Backgrounds” without sacrificing visual quality. “Converters” can adapt images to various formats required for different platforms or printing needs. The concept of “Image-to-Text,” though inverse to Google’s Imagen, also finds relevance as it could be used to generate descriptive metadata for AI-created “Stock Photos” or for accessibility purposes on Tophinhanhdep.com.
Ethical Considerations and Responsible AI in Imaging
As with all powerful AI technologies, particularly those involved in image generation and manipulation, “Imagen” brings with it important ethical considerations. Google’s Imagen researchers themselves highlight concerns regarding potential misuse, the perpetuation of social biases embedded in training data, and the challenges of generating images depicting people fairly. Text-to-image models, by learning from vast, often uncurated web datasets, can inadvertently reflect and amplify social stereotypes, oppressive viewpoints, or harmful associations.
For Tophinhanhdep.com, embracing these technologies means also embracing a responsibility to understand their limitations and potential impacts. Awareness of dataset biases, the importance of responsible prompting, and critical evaluation of AI-generated content are crucial. While these tools offer immense creative liberation, they also necessitate a conscious effort towards ethical implementation, ensuring that the generated “Images” and “Photography” contribute positively to visual culture and avoid perpetuating harmful stereotypes. Responsible use of AI in “Visual Design” means balancing innovation with integrity, a principle that guides the evolution of such powerful technologies.
Conclusion
The term “Imagen” encapsulates a transformative era in visual content creation and manipulation. Google’s Imagen, the generative text-to-image model, stands as a testament to AI’s ability to translate imagination into photorealistic imagery, offering Tophinhanhdep.com users an unparalleled source for unique “Wallpapers,” “Backgrounds,” “Digital Art,” and “Creative Ideas.” Simultaneously, Imagen AI Ltd. provides photographers and visual designers with an intelligent editing assistant, streamlining workflows, ensuring consistency in “Editing Styles,” and optimizing “High Resolution” “Digital Photography” with remarkable efficiency.
Together, these two manifestations of “Imagen” represent a symbiotic relationship between AI-driven generation and AI-enhanced refinement. They empower creators to not only bring any vision to life but also to process and perfect their existing work with newfound speed and precision. For the Tophinhanhdep.com community, the future of images, photography, and visual design is being actively reshaped by these advancements, promising an exciting landscape where creativity is boundless and efficiency is optimized. As we continue to explore and integrate these powerful “Image Tools,” “Imagen” will undoubtedly remain at the forefront of this visual revolution, inspiring, illustrating, and imagining the possibilities yet to come.